
在人工智能领域,国产大模型正以惊人的速度蓬勃发展。今年初,DeepSeek-R1 以超低的运行成本实现了超越 OpenAI 的卓越性能,打破了国外大模型长期以来的垄断局面。如今,MiniMax 带来了更令人振奋的消息:其最新研发的文本转语音(TTS)模型 “Speech-02” 在国际权威的语音评测榜单 Artificial Analysis 上一举夺冠,力压 OpenAI 和行业巨头 ElevenLabs。

Speech-02 凭借在字错率(WER)和说话人相似度(SIM)等关键指标上的卓越表现,刷新了最佳结果(SOTA),引发了国际网友的广泛关注和赞誉,MiniMax 被誉为音频领域的创新先锋。更值得一提的是,Speech-02 的成本仅为 ElevenLabs 竞品的四分之一,展现出超高的性价比。
Speech-02 的卓越成就得益于两项核心技术创新。首先,它实现了真正的零样本(zero-shot)语音克隆技术,仅需一段参考语音,无需额外文本,即可快速生成与目标语音高度相似的音频,极大地节省了时间和资源。其次,MiniMax 首次采用了 Flow-VAE 架构,提升了语音生成过程中的信息表征能力,显著改善了合成音频的质量和相似度。通过引入可学习的 speaker 编码器,Speech-02 能精准捕捉说话者独特的音色、语调和节奏等发音特点,避免了传统语音合成的生硬感。
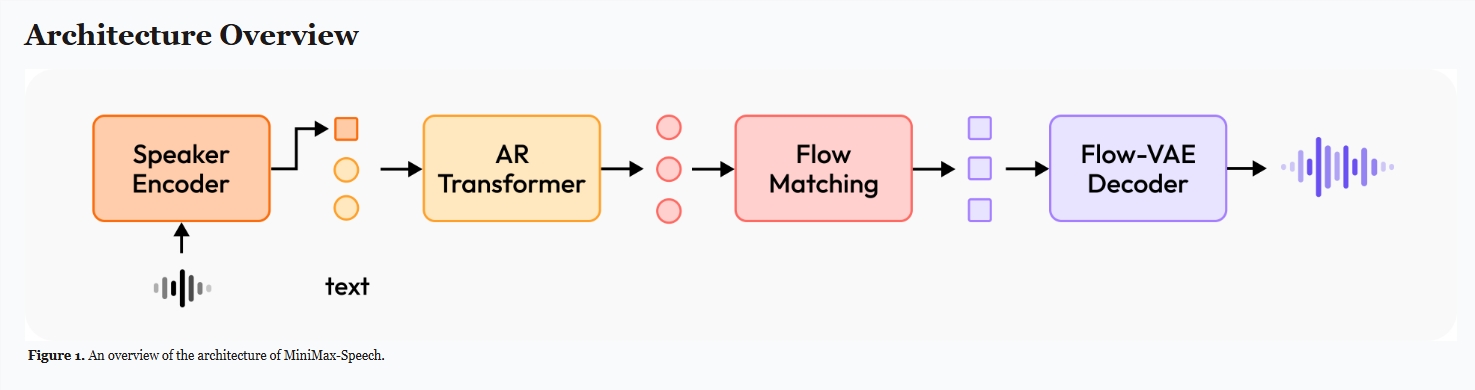
此外,MiniMax 独创的 T2V 框架将开放式自然语言描述与结构化标签信息相结合,进一步增强了语音合成的灵活性和可控性。用户不仅可以提供参考音频,还能通过简单描述生成所需音色的语音,极大地拓展了系统的应用场景。
Speech-02 的成功不仅彰显了国产大模型在语音合成领域的强大实力,也向全球展示了中国在人工智能技术领域的快速崛起和创新能力。这标志着国产大模型在语音合成领域已达到国际领先水平,为未来更多创新应用奠定了坚实基础。
技术文档:https://minimax-ai.github.io/tts_tech_report/

